Hi CMS team,
I have managed to get my SSP245 suite working (u-dq189). I am now trying to get the ozone redistribution code working. The suite runs for the first year, and the first month it is trying to do the redistribution it fails.
The suite fails in the “OZONE” stage within the “redistribute_ozone” step. The job.err is
/work/y07/shared/umshared/iris/python: line 8: 242601 Killed singularity run -B $BIND_POINTS --env=LD_LIBRARY_PATH=$LOCAL_LD_LIBRARY_PATH $SING_SIF “$@”
[FAIL] python_env python ${CYLC_SUITE_DEF_PATH}/src/contrib/redistribute_ozone.py -t $TROPOPAUSE_INPUT -r $OROGRAPHY_INPUT -d $DENSITY_INPUT -z $OZONE_INPUT -o $OZONE_OUTPUT -y $YEAR <<‘STDIN’
[FAIL]
[FAIL] ‘STDIN’ # return-code=137
2025-06-14T02:08:27Z CRITICAL - failed/EXIT
slurmstepd: error: Detected 1 oom-kill event(s) in StepId=9833851.batch. Some of your processes may have been killed by the cgroup out-of-memory handler.
Within the /home/n02/n02/penmaher/cylc-run/u-dq189/share/data/ozone_redistribution/ dir the files are there as expected:
lrwxrwxrwx 1 penmaher n02 81 Jun 12 14:06 qrparm.orog → /work/y07/shared/umshared/ancil/atmos/n96e/orca1/orography/globe30/v6/qrparm.orog
lrwxrwxrwx 1 penmaher n02 63 Jun 12 14:06 model_data → /work/n02/n02/penmaher/cylc-run/u-dq189/share/data/History_Data
lrwxrwxrwx 1 penmaher n02 114 Jun 12 14:06 mmro3_monthly_CMIP6_2014_N96_dq189-ancil_2anc → /work/y07/shared/umshared/cmip6/ancils/n96e/ssp245/Ozone/v1/historic_interpolated_3d_ozone_n96e_2015_2099_ants.anc
lrwxrwxrwx 1 penmaher n02 114 Jun 13 09:13 mmro3_monthly_CMIP6_2015_N96_dq189-ancil_2anc → /work/y07/shared/umshared/cmip6/ancils/n96e/ssp245/Ozone/v1/historic_interpolated_3d_ozone_n96e_2015_2099_ants.anc
lrwxrwxrwx 1 penmaher n02 99 Jun 14 02:58 dq189a.po2015.pp → /work/n02/n02/penmaher/cylc-run/u-dq189/share/data/ozone_redistribution/model_data/dq189a.po2015.pp
So the input to the python call look okay.
I have tried testing the python_env within the site dir.
[penmaher@puma2 site]$ archer2_python_env python
bash: archer2_python_env: command not found…
I am not sure if this is how to test the env properly. I would be interested to hear what you think might be going on.
Thank you!
Penny
Penny
It’s odd that the job ran out of memory. The default memory allocation in the serial queue has been OK for us. As quick test, please try increasing the memory requested - in [[HPC_SERIAL]]
add
–mem=4G
thus:
[[HPC_SERIAL]]
inherit = None, HPC
[[[directives]]]
--ntasks=1
--partition=serial
--qos=serial
--mem=4G
then reload the suite and retrigger the task
Grenville
Hi Grenville,
Thanks for helping. I increased the memory as you suggested in site/archer2.rc, reloaded the suite using rose suite-run --reload and triggered the failed step. I still get the same error.
Penny
Penny
Let’s exhaust this approach before trying something else, you can ask for up to 125 GB, I guess it needs to read in /work/y07/shared/umshared/cmip6/ancils/n96e/ssp245/Ozone/v1/historic_interpolated_3d_ozone_n96e_2015_2099_ants.anc which is 20GB, so maybe try setting mem=100GB .
Grenville
Yes that fixed it. Thanks. I plan to break the files down into smaller chunks but for now I am simply testing to see if it works.
As an FYI for me, how did you diagnose this as a memory issue? The error message pointed me towards a python issue.
Much appreciated.
Penny
the error message you posted says:
Morning CSM team,
My Ozone redistribution code is running for a few months and then blowing up (i.e. the coupled step fails). The run started at 20150101 and failed at 20160501 (model blow up with standard halo out of bounds error).
My suite is u-dq189. At rev @322463 the code is a successfully running a SSP245 suite without ozone redistribution and archiving to Jasmine. The commits since that have added to code to run the redistribution.
I am digging around in the 20160401 data (the month before the suite failed on Jasmin) to see if anything looks suspicious. I noticed that Ozone (0 isec, 60 item) is not outputted. I will add it to my STASH request list. As a point of curiosity, it is also not in u-as037 (but I have misunderstood the stash requests).
The suite is not outputting the extra stash requests from app/um/opt/rose-app-ozone.conf. In my suite the stream pp104 is not used elsewhere but I have linked it to
filename_base=‘$DATAM/${RUNID}a.p0%C’
but this is not outputted, so I have done something wrong but to me it al looks okay. Any ideas?
The above is a bit of an aside, the real problem is that the suite is blowing up and I don’t know why. I have had quite few problems with restart files causing the model to blow up, and it could be this again, or it could be that I have not got the ozone redistribution code in place properly. Could I have help thinking about what might have gone wrong in the new suite code changes please?
Penny
Penny
this
[namelist:umstash_streq(00253_1f5e9a92)]
dom_name='DALLRH'
isec=0
item=253
package=''
tim_name='TMONMN'
use_name='UP4'
says send stash 253 to UP4. UP4 is associated with pp115, which is going to files called $DATAM/${RUNID}a.p4%C. The two fields are there.
So I think you don’t need a new output stream (pp104.)
ozone redistribution created
/work/n02/n02/penmaher/cylc-run/u-dq189/share/data/etc/ozone/mmro3_monthly_CMIP6_2016_N96_dq189-ancil_2anc
which looks OK.
DId the model run past 2016 with ozone switched off?
(please switch off housekeeping until you have the suite running stably)
Grenville
Hello,
Sorry for the delay.
In testing the suite I ran it out for a year (with ozone off) but in hindsight this was not long enough. So I have rerun it for two years with ozone redistribute off. So this is an ozone redistribution specific problem.
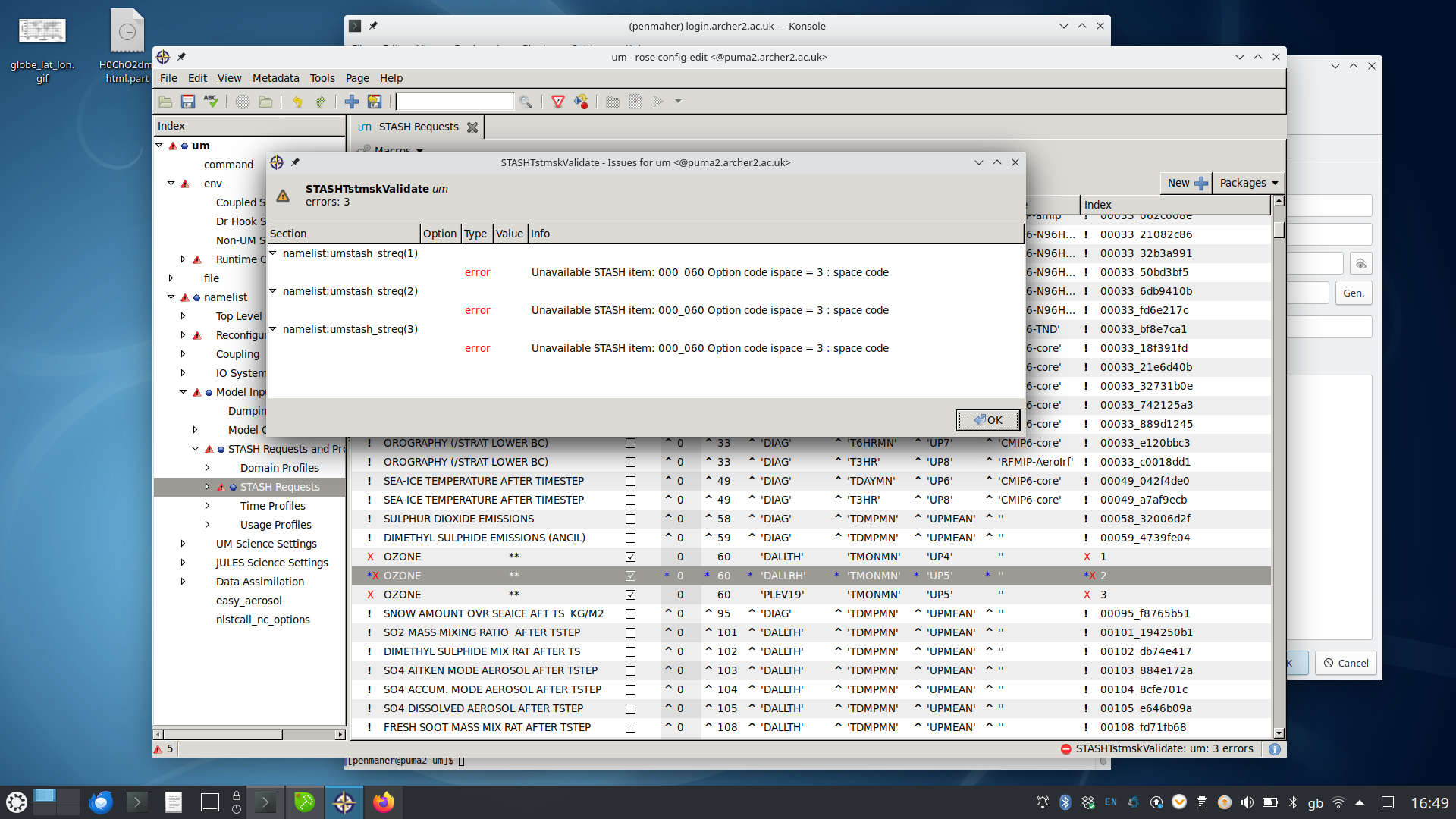
I have tried adding ozone (stash item 0,60) to the stash requests, but interestingly I can’t get it working. I put the stash request in, ran the suite and then realised it was not working. When I validate the stash request I get the attached error message.
In the suite, I added three ozone profiles, one for theta levels, one for rho levels and one for the 19 level interpreted onto pressure levels (just to test if this was a issue related to the vertical profile I selected). This is why there are 3 requests for ozone coming up in this error.
I don’t believe this is an issue related to my suite. When I try to add ozone to the piControl archer2 supported suite u-as037 I also get the same problem. Interestingly when I try to add a stash request that is not related to ozone, everything works fine.
I was at the Met Office yesterday and asked two different people. The impression I was left with, is that this could be a STASHmaster_A issue, or a meta data issue. I got the impression this might be an archer2 specific issue but perhaps that is not the case.
Does this look like an error anyone has seen before?
Penny
Penny
I have take a copy of your suite, but don’t get the stash validation errors you get. Nor do I have a problem adding ozone stash to u-as037. Not sure how to proceed.
Grenville
Hmm. That is rather strange indeed! I wonder what is going on…
Morning,
Could we brainstorm some ideas we could try? I am either incorrectly requesting the ozone stash request (which at this point feel unlikely) or I have changed something within my environment (perhaps while setting up the ozone redistribution) that maps across all my suits. Any thoughts on where I could start looking at this? I have asked a few people at the MO and this is not a common problems so I have not been able to resolve it yet.
Penny
Penny
Is the suite unchanged from the last time I looked (stilll u-dq189?)– maybe best to point me to the latest version (ideally one that lives in MOSRS so we have a concrete starting point.()
Grenville
Hi Grenville,
I had been playing in the rose edit stash requests. I have committed these changes. Yes the suite is u-dq189 and the version on https://code.metoffice.gov.uk/trac/roses-u/browser/d/q/1/8/9/trunk is the same as the copy I have on puma.
Penny
Penny
I’ve lost track of the problem - is it that ozone is not written out as a diagnostic - if so, then, that is to be expected given what is written in https://code.metoffice.gov.uk/doc/um/vn13.7/papers/umdp_C04.pdf (see page 22) – the Space code for ozone is 3 - so …primary field unavailable to STASH…
ozone is held in the dump, but it’s just taken from the ancillary files anyway,
I am running the suite now to see if it’s behaving.
Grenville
The problem summary is as follows:
- The suite is an SSP245 run
- The suite is working when ozone redistribution is off (2 years runs fine).
- When I turn on ozone redistributions, the first year runs fine (when ozone redistribution does nothing) and then at month 4 or 5 (I can’t remember which month now) of year two of the simulation the model crashes.
- I am trying to diagnose if the ozone redistribution caused it to crash, or if I was just unlucky and hit a standard halo of bounds error.
To test if the ozone redistribution is working, I wanted to output Ozone so I could compare to https://cms.ncas.ac.uk/unified-model/ozone-redistribution/ and see if I had the banding.
Penny
Penny
The suite with ozone-redistribution (OR) failed in month 5 of 2016. The ozone files look OK - I perturbed the start file for 20160501 and allowed it to run on - it’s running happily. Perturbing the dump is a common way to try to get a model going (perturbation is at the bit level)
(see /home/n02/n02/grenvill/cylc-run/u-dq189/share/data/History_Data/submit_perturb.slurm for how to perturb)
Maybe give that a try?
Grenville